Hierarchische Strukturen mit Closure Tables in SQL zu implementieren, stellt den dritten und letzten Beitrag dieser dreiteiligen Kurzreihe dar, die sich mit hierarchischen Strukturen, deren Modellierung und SQL-Implementierung beschäftigt.
Im ersten Beitrag haben wir uns mit der Modellierung hierarchischer Strukturen mithilfe von Adjazenzlisten beschäftigt. Der zweite Beitrag behandelte die Implementierung mithilfe von Nested Sets.
Hierarchische Strukturen mit Closure Tables
Hierarchischen Strukturen mit Closure Tables abzubilden, ist eine einfache und elegante Art und Weise, Hierarchien, ohne die Notwendigkeit rekursiver Datenbankfunktionalität, zu implementieren. Die grundlegende Idee dabei ist es, alle Pfade im Baum, nicht nur die direkten Beziehungen zwischen zwei Knoten, in einer sogenannten Closure Table zu speichern. Sie ähnelt einer Adjazenzliste, speichert aber neben den direkten auch die indirekten Beziehungen.
Modellierung
Wir nutzen die schon bekannte Personaltabelle und spendieren uns eine Tabelle namens personal_closure. Hierin speichern wir alle direkten und indirekten Beziehungen zwischen den Mitarbeiten (Knoten).
|
1 2 3 4 5 6 7 |
CREATE TABLE personal_closure ( vnr INTEGER REFERENCES personal (mnr) ON UPDATE CASCADE, mnr INTEGER REFERENCES personal (mnr) ON UPDATE CASCADE, tiefe INTEGER NOT NULL DEFAULT 0, PRIMARY KEY (vnr, mnr) ); |
Das Attribut tiefe gibt die Pfadlänge der jeweiligen Relation an. Es ist für die Modellierung nicht zwingend erforderlich, vereinfacht aber die Abfrage der Ebenen.
Einfügen von Daten
Jeder Mitarbeiter wird zuerst als sein eigener Vorgesetzter erfasst.
|
1 2 3 |
INSERT INTO personal_closure (vnr, mnr) SELECT mnr, mnr FROM personal; |
Nun sind die direkten und indirekten Beziehungen zu den jeweils anderen Mitarbeitern zu speichern.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
-- Jetzt sagen wir der CLosure-Tabelle, dass Sebastian ein -- Mitarbeiter von Wolfgang ist INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 1 AND b.vnr = 2; -- -> 1, 2, 1 -- das muss nun für jede Beziehung in der Personalhierarchie getan werden! -- Mario INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 2 AND b.vnr = 3; -- -> 2, 3, 1 -- -> 1, 3, 2 -- Lisa INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 1 AND b.vnr = 4; -- -> 1, 4, 1 -- Silke INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 4 AND b.vnr = 5; -- -> 4, 5, 1 -- -> 1, 5, 2 -- Bernd INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 5 AND b.vnr = 6; -- -> 5, 6, 1 -- -> 4, 6, 2 -- -> 1, 6, 3 -- Rainer INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 5 AND b.vnr = 7; -- -> 5, 7, 1 -- -> 4, 7, 2 -- -> 1, 7, 3 -- Robert INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 4 AND b.vnr = 8; -- -> 4, 8, 1 -- -> 1, 8, 2 -- Marius INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe + b.tiefe + 1 FROM personal_closure a, personal_closure b WHERE a.mnr = 4 AND b.vnr = 9; -- -> 4, 9, 1 -- -> 1, 9, 2 |
Wir nutzen hierzu das jeweilige Kreuzprodukt, welches sich ergibt, wenn wir die Tabelle mit sich selbst in Beziehung setzen und mnr und vnr als einschränkende Bedingung definieren. – Trickreich!
Hierarchische Strukturen mit Closure Tables bedingen relativ komplexe Einfügeoperationen.
Abfragen
Grafisch ergibt sich nach den Einfügeoperationen das folgende Bild:
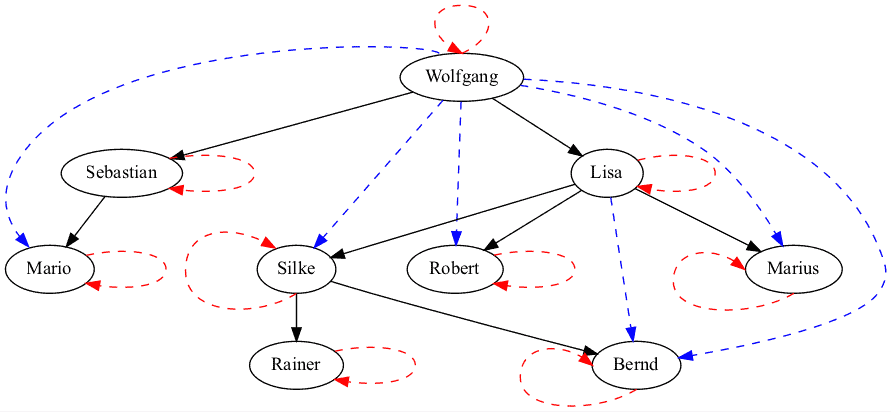
Die schwarzen Pfeile definieren die hierarchischen Beziehungen. Die roten Pfeile stellen die Selbstbezüge dar und die blauen Pfeile zeigen die indirekten Beziehungen zwischen den Mitarbeitern/Knoten.
Weil alle Beziehungen zwischen den Knoten gespeichert sind, ist eine Abfrage, die nach den Vorgängern oder Nachfolgern eines Knotens fragt, extrem einfach zu realisieren.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- alle Vorgesetzten eines Mitarbeiters (Bernd, 6) SELECT vnr FROM personal_closure WHERE mnr = 6 AND tiefe != 0 ORDER BY tiefe DESC; -- dto. mit Namen SELECT a.vnr, mitarbeiter FROM personal_closure a JOIN personal b ON a.vnr = b.mnr WHERE a.mnr = 6 AND tiefe != 0 ORDER BY tiefe DESC; -- alle direkten Untergebenen einer Person (Lisa, 4) SELECT a.mnr, b.mitarbeiter FROM personal_closure a JOIN personal b ON a.mnr = b.mnr WHERE a.vnr = 4 AND tiefe = 1; -- Einschränkung auf direkt Untergebene |
Löschen eines Blattes
Einen Blattknoten zu löschen ist einfach. Dazu werden einfach alle Datensätze in der Closure Table gelöscht, die den zu löschenden Datensatz referenzieren (vnr). Weil sich jeder Datensatz selbst referenziert, reicht diese eine Bedingung aus.
|
1 2 3 4 |
-- Bernd (6) löschen DELETE FROM personal_closure WHERE mar = 6; |
Beachte: Dieses Vorgehen gilt nur für Blätter, nicht für Knoten, die Kindknoten besitzen!
Löschen eines Teilbaumes
Das Löschen eines ganzen Teilbaums ist ähnlich trivial, wie das Entfernen einzelner Blätter. Dazu fragen wir lediglich, welche Nachfolger der Knoten hat, dessen Teilbaum wir löschen wollen. Alle sich ergebenden Knoten sind zu löschen.
|
1 2 3 4 5 6 |
-- Teilbaum von Lisa (4) löschen DELETE FROM personal_closure WHERE mnr IN (SELECT mnr FROM personal_closure WHERE vnr = 4); |
Verschieben eines Teilbaumes
Das Verschieben eines Teilbaums ist nicht nur Selbstzweck, es ist auch immer dann erforderlich, wenn ein Knoten, der Nachfolger besitzt gelöscht werden soll und seine Nachfolger einem anderen Knoten zugewiesen werden sollen.
Zuerst löscht man alle Datensätze in der Closure Table, die direkte und indirekte Pfade von Vorgängern zur Teilbaumwurzel oder deren Nachfolger beschreiben. Soll der Teilbaum von Lisa (4) unter Sebastian (2) geschoben werden, sind folgende Beziehungen zu löschen: (1,4), (1,5), (1,6), (1,7), (1,8), (1,9). Das besorgt ein DELETE-Statement.
Die Informationen zur Struktur des Teilbaums sind noch erhalten. Analog zum bereits bekannten Einfügen, fügen wir die sich beim Verschieben ergebenden Beziehungen in die Closure Table ein.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
-- Lisa (4) inkl. Teilbaum unter Sebastian (2) verschieben -- -- Löscht alle Beziehungen von der Wurzel zur 4 -- sowie die Pfade von der Wurzel zu den Nachfolgern von 4 DELETE FROM personal_closure WHERE mnr IN (SELECT mnr FROM personal_closure WHERE vnr = 4) AND vnr IN (SELECT vnr FROM personal_closure WHERE mnr = 4 AND vnr != 4); -- jetzt gelöscht: -- 1,4,1 -- 1,5,2 -- 1,6,3 -- 1,7,3 -- 1,8,2 -- 1,9,2 -- -- Teilbaum an neuer Position einfügen INSERT INTO personal_closure (vnr, mnr, tiefe) SELECT a.vnr, b.mnr, a.tiefe+b.tiefe+1 from personal_closure a cross join personal_closure b WHERE a.mnr = 2 AND b.vnr = 4; -- eingefügt: -- 2,4,1 -- 1,4,2 -- 2,5,2 -- 1,5,3 -- 2,6,3 -- 1,6,4 -- 2,7,3 -- 1,7,4 -- 2,8,2 -- 1,8,3 -- 2,9,2 -- 1,9,3 |
Damit wurde der Teilbaum, dessen Wurzel Lisa bildet, unter Sebastian verschoben.
Hierarchische Strukturen mit Closure Tables – Zusammenfassung und Vergleich
Vielleicht fragen Sie sich, warum ich nicht auch die Pfadenumeration vorgestellt habe. Sie benötigt ein Zeichenkettenfeld für den Pfad. Dieses ist, je nach Datenbankmanagementsystem, in seiner Länge limitiert. Weil nun die Länge der zu speichernden Knoten in der Pfad-Zeichenkette variieren kann, kann man keine konkrete Tiefe angeben, die so gespeichert werden kann. Außerdem sind die erforderlichen Zeichenkettenoperationen aufwendig. Für kleine Menüsysteme auf Webseiten mag die Pfadenumeration daher geeignet sein, für größere Hierarchien ist sie es, aus meiner Sicht, nicht.
Die vorgestellten Modellierungen sind in unterschiedlicher Ausführlichkeit diskutiert worden. Das hat seinen Grund. Seit quasi alle gängigen Datenbankmanagementsysteme rekursive Abfragen beherrschen, sind Adjazenzlisten sicherlich das erste Modell der Wahl. Sie spielen insbesondere dann ihre Vorteile aus, wenn sehr viel Bewegung in den Daten ist. Nachteilig ist die Komplexität der Abfragen in Bezug auf die Ausführungsgeschwindigkeit – die Formulierung ist einfach, wenn man Rekursion verstanden hat. Rekursionen sind letztlich ineinander verschachtelte Schleifen. Sie kosten leider Rechenzeit.
Bei den Nested Sets und den Closure Tables sind Abfragen dagegen sehr einfach und schnell. Insbesondere die Closure Tables glänzen hier durch Einfachheit und Geschwindigkeit. Im Prinzip sind sie den Adjazenzlisten nicht unähnlich. Jedoch werden bei ihnen die gesamten Strukturinformationen durch „geschicktes Vorgehen“ beim Einfügen der Knoten generiert und gespeichert. So muss diese Information nicht mühsam rekursiv rekonstruiert werden, wie dies bei den Adjazenzlisten der Fall ist. Nachteilig ist die Vielzahl der Datensätze und deren korrekte Verwaltung. Nested Sets benötigen deutlich weniger Datensätze, die Abfragebedingungen sind für ein Datenbankmanagementsystem einfach zu optimieren, so dass sie vor allem durch ihre Abfragegeschwindigkeit glänzen. Dafür sind die Regeln, welche die Struktur bestimmen, einigermaßen trickreich und komplex. Strukturänderungen haben weitreichende Änderungen an weiteren Datensätzen innerhalb einer Struktur zur Folge, weil deren Nummerierung stets angepasst werden muss. Für Datenbestände, die vielen strukturellen Änderungen unterworfen sind, sind Nested Sets daher nicht geeignet.
| Modell | Kindknoten abfragen |
Baum abfragen |
INSERT | DELETE | UPDATE |
|---|---|---|---|---|---|
| Adjazenzliste | einfach | einfach | einfach | einfach | einfach |
| Nested Set | schwieriger | schwieriger | schwer | schwer | schwer |
| Closure Table | einfach | einfach | schwer | schwer | schwer |
Die Tabelle stellt die verschiedenen Aspekte verkürzt dar. In der Tat erfreuen sich Nested Sets einer großen Beliebtheit. Einen entscheidenden Nachteil haben sie jedoch: Sie unterstützen keine referentielle Integrität, was ich für einen wirklich großen Nachteil halte.
Unter dem Strich entscheiden jedoch die spezifischen Anforderungen, welches Modell das geeignete ist. Mit entscheidend sind auch das zur Verfügung stehende Datenbankmanagementsystem und dessen Fähigkeiten. So lassen sich Nested Sets und Closure Tables auch mit einer alten MySQL-Datenbank Version 5.x abbilden. Mangels rekursiver Abfragemöglichkeiten wären hier Adjazenzlisten weniger geeignet. Wollte man sie dennoch verwenden, so müsste man prozeduralen Code schreiben, um eine Hierarchie geeignet traversieren zu können.
Wenn auch bei den Neseted Sets und den Closures Tables nicht im Detail diskutiert, so dürfte klar sein, hier den größten Aufwand betreiben zu müssen, um die Integrität der Daten sowie der Struktur gewährleisten zu können.
Am Ende ist es eine nicht ganz einfache Entscheidung, welches Modell für eine konkrete Implementierung gewählt wird. Wichtig ist jedoch, so meine ich, die verschiedenen Alternativen zu kennen, um eine begründete Entscheidung treffen zu können.
Teil 2: Hierarchische Strukturen mit Nested Sets