
PDF-Dateien sind die erste Wahl, wenn es darum geht Dokumente weiterzureichen oder auch zu archivieren. Sie sind grundsätzlich unveränderlich für den Empfänger, was die Sicherheit, den Inhalt des Dokuments vor unbeabsichtigten Änderungen zu schützen, ungemein erhöht. Auch sind PDF-Dateien im Rahmen der digitalen Archivierung nicht wegzudenken. Kurz: PDF-Dateien spielen in der täglichen Praxis, insbesondere in der Praxis des Unternehmensalltags, eine ganz zentrale Rolle.
Im Folgenden zeige ich, wie man PDF-Dateien komfortabel und flexibel bearbeiten kann. Ich habe hier unter macOS 10.12 (Sierra) gearbeitet. Die verwendete Software ist jedoch auch für andere Plattformen verfügbar.
PDF-Dateien erstellen
Im Dialog zum Drucken von Dokumenten bringt der Mac bereits alles mit, was zum erstellen von PDF-Dateien erforderlich ist. Selbiges gilt in analoger Form auch für Gnu/Linux oder Microsoft Windows. Aus einer Textverarbeitung oder einem Texteditor heraus gedruckt, sind diese Dokumente auch durchsuchbar. Was ist jedoch mit gescannten Dokumenten, die Textseiten als Grafik beinhalten? Wie lassen sich diese zum Durchsuchen nach Textpassagen aufbereiten? Wie lassen sich PDF-Dokumente in einzelne Seiten zerlegen oder umgekehrt aus verschiedenen einzelnen Dokumenten in einer Datei zusammenfassen? – Einige Funktionen bringen die in macOS integrierte Vorschau-App oder auch Skim, ein potenter PDF-Viewer, mit. Richtig gut wird es jedoch erst, wenn wir ein paar zusätzliche Werkzeuge installieren.
OCR – Texterkennung
Wenn wir Dokumente selbst erstellen, beispielsweise mit Microsoft Word, LibreOffice, OpenOffice oder LaTeX, können wir die daraus resultierenden PDF-Dokumente nach in ihnen enthaltenen Textpassagen durchsuchen. Dazu öffnen wir unseren bevorzugten PDF-Betrachter und legen los.
Viele eingehende Dokumente werden heutzutage eingescannt. Das Resultat ist eine Bilddatei oder eine PDF-Datei, in der ein Bild des gescannten Dokuments eingebettet ist. Durchsuchbar sind diese Dateien nicht. Ein Dokument nach bestimmten Textpassagen durchsuchen zu können, ist jedoch gerade eine der Stärken des PDF-Formats. Wie schaffen wir es also, eine gescanntes Dokument durchsuchbar zu machen? – Wir benötigen neben der Bild- auch die Textinformation. Um diese zu erhalten, müssen wir unsere Dokumente mit einer OCR-Software (Optical Character Recognition), einer Texterkennung, bearbeiten.
tesseract – freie OCR-Software
Auf dem Mac empfiehlt sich hierzu die OCR-Engine tesseract. Die hier vorgestellten Tools lassen sich leicht via MacPorts oder auch HomeBrew, zwei Paket-Repositories für den Mac, nachinstallieren. Für andere Betriebssysteme gibt es entsprechende Repositories. In den Repos der üblichen Linux-Distributionen ist regelmäßig alles vorhanden. Alternativ können Sie sich die erforderliche Software auch selbst aus den Quellen übersetzen. Die GitHub-Archive leptonica und tesseract enthalten (fast) alles, was Sie zum Selbstbau benötigen. – Sie sollten sich dann natürlich über die erforderlichen Entwicklungswerkzeuge verfügen und sich mit dem Übersetzen und Montieren von Software etwas auskennen. Hinweis: Beachten Sie beim Eigenbau unbedingt die Hinweise auf den jeweiligen Archivseiten. Installieren Sie insbesondere auch die für Sie erforderlichen Sprachdateien, die auf der tesseract-Seite verlinkt sind. Welche Grafikdateiformate unterstützt werden, hängt von den vorhandenen Bibliotheken ab, mit denen die Programme übersetzt werden.
tesseract kann vermutlich am einfachsten über die oben angegeben Repositories installiert werden. – Hierbei ist, wie auch beim Selbstbau, unbedingt zu beachten, auch die benötigten Sprachpakete mit zu installieren. Englisch ist Pflicht. Ohne dieses Sprachpaket verweigert tesseract den Dienst.
Ich habe mich für den Selbstbau entschieden und mir die notwendigen Archive von GitHub heruntergeladen, ausgepackt, übersetzt und installiert. Ich musste diverse Abhängigkeiten auflösen, also Bibliotheken nachinstallieren. Das galt auch für die später in diesem Artikel verwendete Software OCRmyPDF und pdfgrep. – Das Ganze ist kein Buch mit sieben Siegeln, erfordert aber eindeutig Erfahrung!
Ist die Software korrekt installiert, lassen sich mit folgenden Befehl die installierten Sprachpakete ausgeben.
|
1 2 3 4 5 6 |
$ tesseract --list-langs List of available languages (3): deu eng osd $ _ |
Das OSD-Sprachpaket ist erforderlich, um die Orientierung eines Scans oder auch mehrspaltigen Satz korrekt zu erkennen.
Textinformationen aus Bildern gewinnen

Nun wollen wir erstmal aus einem Bild die Textinformationen extrahieren. Dazu habe ich als Beispiel eine Seite aus einer Zeitschrift zum Falten von Papierfliegern gescannt.
Ich habe hier ein Dokument im TIF-Format verwendet. tesseract bedient sich der Bildbearbeitungsbibliothek Leptonica. Alle Bildformate, die Leptonica verarbeiten kann, können auch mit tesseract genutzt werden.
Mit dem folgenden Befehl können wir den Textinhalt erkennen und als Textdatei speichern:
|
1 2 3 4 |
$ tesseract -l deu scan.tif scan Tesseract Open Source OCR Engine v3.04.01 with Leptonica Page 1 $ _ |
Die Texterkennung ist sehr gut, jedoch auch nicht immer perfekt. Wer ganz pedantisch ist, hat jetzt die Möglichkeit, den erkannten Text nachzubearbeiten. Hier ein Ausschnitt aus der generierten Textdatei, ohne diese vorher nachbearbeitet zu haben:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Aero dynamlh Auf ein fliegendes Flugzeug wirken vier Kräfte ein, die in einem bestimmten Verhältnis zueinander stehen müssen: Schwerkraft, Auftrieb, Schub und Luft- widerstand. Da das Eigengewicht eines Flugzeugs schwerer als Luft ist, wird es durch die Schwerkraft zu Boden gezogen. Damit das Flugzeug durch die Luft fliegen kann, muss eine der Schwerkraft ent- gegengesetzte Kraft, der Auftrieb, gebildet werden. Er entsteht durch die Luft selber, die auf eine bestimmte Art und Weise die Tragflächen eines Flugzeuges umströmt. Auf der Tragflächenoberseite entsteht ein Sog, der das Flugzeug nach oben zieht, an der Untersei- te entsteht Druck, der es zusätzlich nach oben drückt. |
Die Überschrift, das Wort „Aerodynamik“ wurde nicht korrekt erkannt. Der Rest des Textes entspricht jedoch perfekt dem Originaltext. Da es bei der folgenden PDF-Verarbeitung vor allem darum geht, die Texte durchsuchbar zu machen, sind kleine Mankos nicht dramatisch.
Texte in PDF-Dateien einbetten
Ein gescanntes Dokument ist vorerst nur ein Bild. Auch wenn wir direkt ins PDF-Format scannen, haben wir nur ein entsprechend eingebettetes Bild. Dieses gilt es nun mittels OCR-Software zu bearbeiten und die erkannten Textpassagen in die PDF-Datei als Textlayer einzubetten.
Bilder in PDF-Dateien bearbeiten – OCRmyPDF beschaffen
Für diesen Job gibt es zum Beispiel OCRmyPDF. Die Software lässt sich anhand der Installationsanleitung leicht installieren. Die erforderlichen Voraussetzungen habe ich mittels des MacPorts-Repositories geschaffen. In der Folge heißen einige Installationsbefehle dann anders als in der Dokumentation von OCRmyPDF beschrieben, was der Sache aber keinen Abbruch tut. Hinweis: Die in MacPorts enthaltene Version von unpaper war zu alt. OCRmyPDF fordert Version 6.1. Ich habe mir das Paket bei GitHub besorgt uns selbst kompiliert.
OCRmyPDF – Bedienhinweise
Ist OCRmyPDF erfolgreich installiert, können wir uns ans Werk machen. Hier erstmal die wichtigsten Optionen, mit denen OCRmyPDF gesteuert wird.
| Option | Funktion |
-h |
Hilfefunktion |
-v |
Ausführlichkeit der Meldungen erhöhen (diese Option kann mehrfach verwendet werden) |
-k |
Temporärdateien nicht löschen |
-g |
Debug-Modus |
-d |
Jede Seite vor der Texterkennung geraderücken (mit convert aus ImageMagick) |
-c |
Jede Seite vor Texterkennung säubern (mit unpaper) |
-i |
Das gesäuberte Bild in der Ausgabe-PDF-Datei verwenden |
-o |
Falls die Auflösung eines Vorlagebildes niedriger sein sollte als die per Argument angegebene Auflösung in dpi, wird für die Texterkennung ein „oversampled“ Bild mit der angegeben Auflösung erstellt. Dadurch kann die Texterkennung verbessert werden. |
-f |
Erzwingen der Texterkennung für das gesamte Dokument, selbst wenn einige Seiten Textdaten enthalten. |
-l |
Angabe der Sprache in der PDF-Datei. Standard ohne Angabe ist Englisch. |
-C |
Angabe einer zusätzlichen Tesseract-Konfigurationsdatei. |
OCRmyPDF – Praxisbeispiel
Die weiteren Optionen sind selbsterklärend. Ich nutze sie hier, um die Meta-information in das zu erstellende PDF-Dokument zu integrieren.
|
1 2 3 4 5 6 7 8 9 10 |
$ ocrmypdf -l deu -c -d -i \ >; --title 'Aerodynamik' \ > --author 'OZ-Verlags-GmbH, Rheinfelden' \ > --subject 'Tolle Papierflieger' \ > --keywords 'Papierflieger Faltmodelle Aerodynamik' \ > scan.pdf papierflieger.pdf INFO - 1: [tesseract] Info in fopenReadFromMemory: work-around: writing to a temp file INFO - Output file is a PDF/A-2B (as expected) $ _ |
Fertig ist das PDF-Dokument.
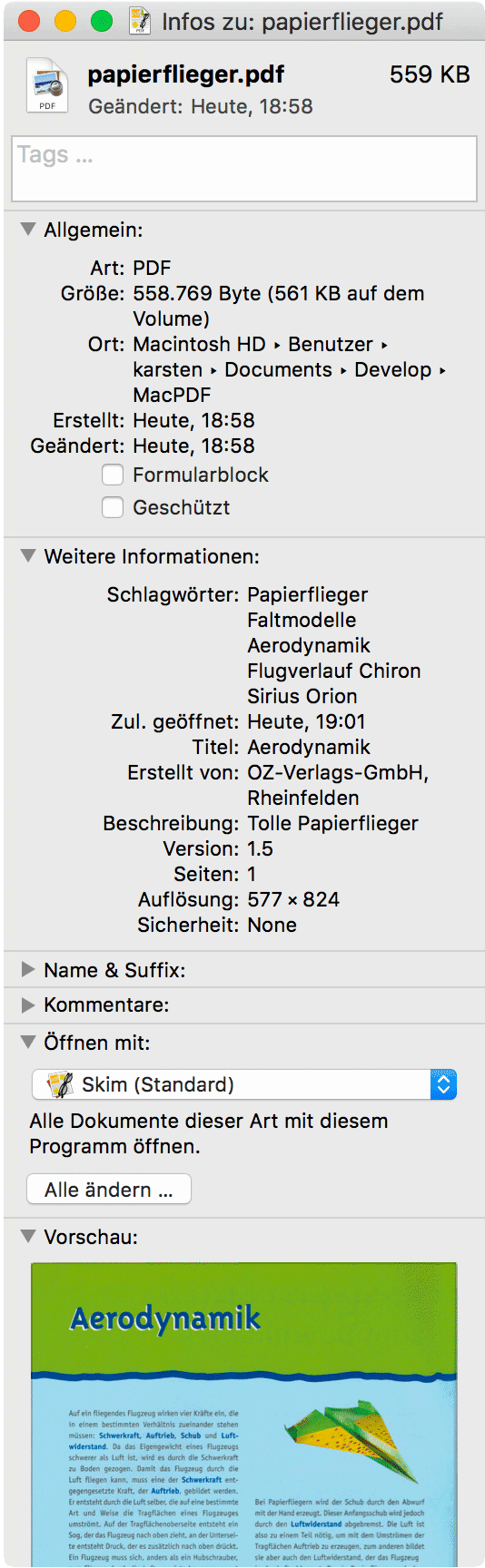

Das Ganze funktioniert natürlich auch mit mehrseitigen Dokumenten.
Auf diese Art und Weise ist das gescannte Dokument jedenfalls bereit für die Langzeitarchivierung. Und das Schöne daran ist, dass man nicht nur im PDF-Viewer nach Schlagwörtern oder Textpassagen suchen kann. Man kann sie natürlich auch markieren, Notizen anheften und so weiter.
PDF-Dateien durchsuchen
Wer nicht immer den PDF-Viewer starten oder gar mehrere Dokumente gleichzeitig durchsuchen möchte, der kann pdfgrep verwenden. Dieses kleine und schnelle Werkzeug kann ganze Verzeichnishierarchien durchforsten und so die Suche nach einem bestimmten Dokument deutlich vereinfachen. Das entspricht nicht dem Komfort einer Volltextsuche, wie sie uns ein Dokumentenmanagementsystem bieten würde, ist dafür aber ohne zusätzlichen Aufwand direkt nutzbar.
|
1 |
$ pdfgrep -i -n 'Schwerkraft' papierflieger.pdf |
Hier die gekürzte Ausgabe:
|
1 2 3 |
1:müssen: Schwerkraft, Auftrieb, Schub und Luft- 1:schwerer als Luft ist, wird es durch die Schwerkraft 1:Luft fliegen kann, muss eine der Schwerkraft ent- |
Der obige Befehl ist etwas „überladen“, weil das zu durchsuchende Dokument nur eine Seite hat. Die Option „-n“ zeigt nämlich die Seitenzahl des Fundortes einer Textpassage an. „-i“ steht für ignore case, so dass die Groß-/Kleinschreibung bei der Suche ignoriert. wird.
Dies ist nur ein kleiner Ausschnitt dessen, was wir mit PDF-Dateien anstellen können. – Es wird eine Fortsetzung geben, die sich dann mit dem Filettieren, dem Zusammenfügen und anderen spannenden Dingen befasst, die wir noch mit PDF-Dateien anstellen können.
Karsten Brodmann